

Kita akan belajar untuk menggunakan Hadoop Cluster di Amazon EMR untuk menganalisis log dengan Hive
Sebelum lanjut pada AWS Case ini pastikan anda sudah membaca artikel sebelumnya “Membuat Hadoop Cluster di EMR“
Pada kasus ini kita akan mencoba melakukan analisis log yang berasal dari Amazon CloudFront log files. Dataset ini sudah tersedia di s3://us-east-1.elasticmapreduce.samples/cloudfront/data/* yang contoh lognya adalah seperti ini
2014-07-05 20:00:00 LHR3 4260 10.0.0.15 GET eabcd12345678.cloudfront.net /test-image-1.jpeg 200 - Mozilla/5.0%20(MacOS;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20IE/3.0.9Dari log files ini kita akan melakukan analisis untuk menghitung jumlah total request per sistem operasi selama jangka waktu tertentu . Untuk penyimpanannya kita akan gunakan Amazon S3
Pertama buat terlebih dahulu Hadoop Cluster seperti pada tutorial “Membuat Hadoop Cluster di EMR” dan remote master agar bisa diakses secara lokal
Note : Jika error membuat cluster pastikan dihapus dulu inbound ssh rule saat pertama membuat hadoop cluster

Setelah sukses masuk di node master, kita akan copy kode hive yang telah disediakan oleh AWS
hadoop fs -copyToLocal s3://us-east-1.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q .Kalau kita buka file Hive_CloudFront.q dengan aplikasi nano maka kodenya adalah seperti ini
nano Hive_CloudFront.q
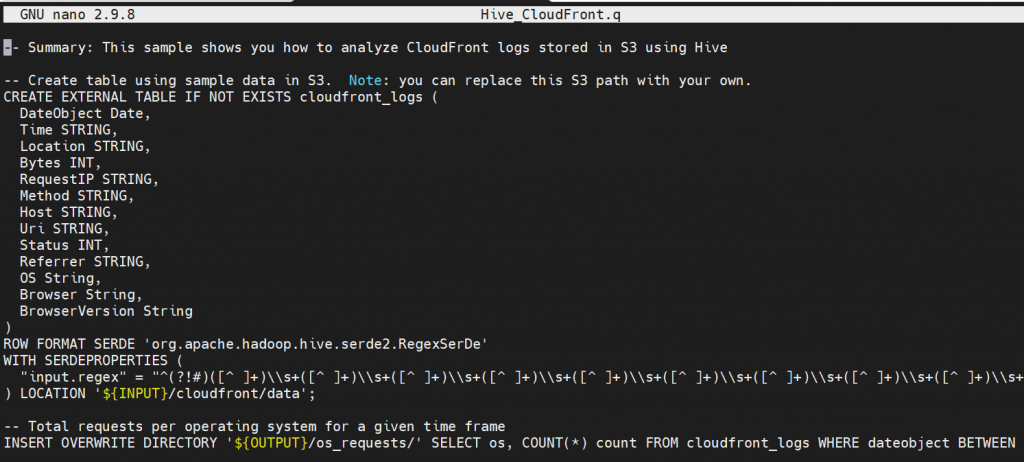
‘{INPUT} ‘dan ‘{OUTPUT}’ merupakan lokasi folder di Bucket Amazon S3
Misalnya kita punya bucket thisismyfirstemrbucket dan ada 2 folder yaitu input dan output
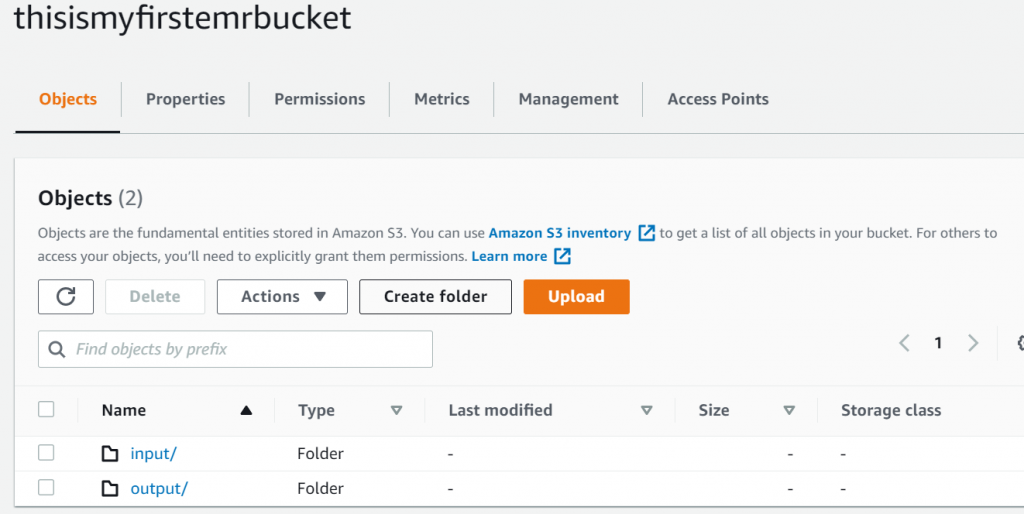
Di dalam folder input buat folder cloudfront
Di dalam folder cloudfront buat folder data untuk menyimpan datanya
Di EMR Console, buat directory cloudfront dan didalamnya bikin directory data seperti halnya di Amazon S3
mkdir cloudfront
cd cloudfront
mkdir data
cd dataSaat berada di directory data copy dataset ke Hadoop Cluster
hadoop fs -copyToLocal s3://us-east-1.elasticmapreduce.samples/cloudfront/data/* .
Copy dataset yang sudah berada di Hadoop Cluster kita ke S3 dengan directory tujuan adalah s3://thisismyfirstemrbucket/input/cloudfront/data/
hadoop fs -copyFromLocal * s3://thisismyfirstemrbucket/input/cloudfront/data/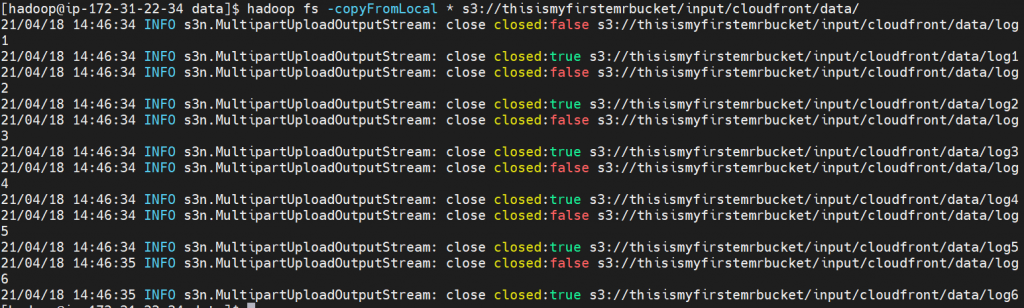
Kita cek di folder input/cloudfront/data di S3 bucket thisismyfirstemrbucket
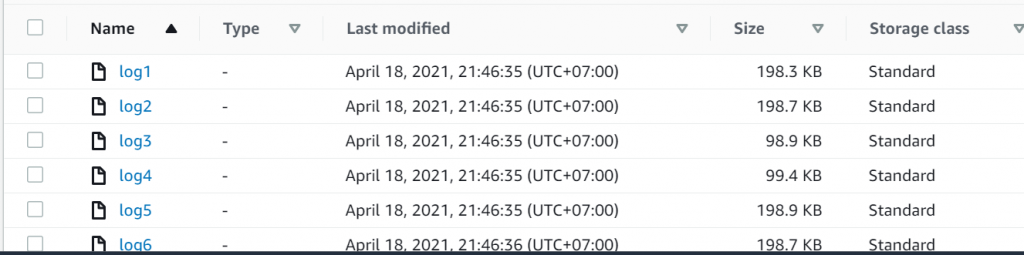
Oke datanya sudah masuk
Kemudian kembali ke console dan masuk di directory home dan copikan file Hive.p ke bucket thisismyfirstemrbucket
cd ../../
hadoop fs -copyFromLocal Hive_CloudFront.q s3://thisismyfirstemrbucket/Cek di bucket S3

Buka Amazon EMR dan masuk Tab Steps, tambahkan step dengan klik Add Step

Masukkan
Type: hive program
Browse Script S3 location di Hive_CloudFont.q
Browse S3 Input location di folder input
Browse S3 Output location di folder output
Masukkan argumen
-hiveconf hive.support.sql11.reserved.keywords=false
klik Add

Tunggu status dari pending ke status completed

dan download hasil script Hive di folder output di bucket S3

Kalau kita buka menggunakan Editor hasilnya adalah
Linux813
MacOS852
OSX799
iOS794Dari hasil ini kita bisa pahami bahwa jumlah total request per sistem operasi yang paling banyak adalah MacOS sebanyak 852 requests, Linux sebanyak 813, OSX sebanyak 799 dan iOS sebanyak 794
Oke sekian tutorial implementasi Hadoop Cluster di Amazon EMR untuk menganalisis log dengan Hive. Semoga bermanfaat
** Jangan lupa terminate Hadoop cluster jika sudah tidak digunakan